搜索到
81
篇与
的结果
-

-
-
-
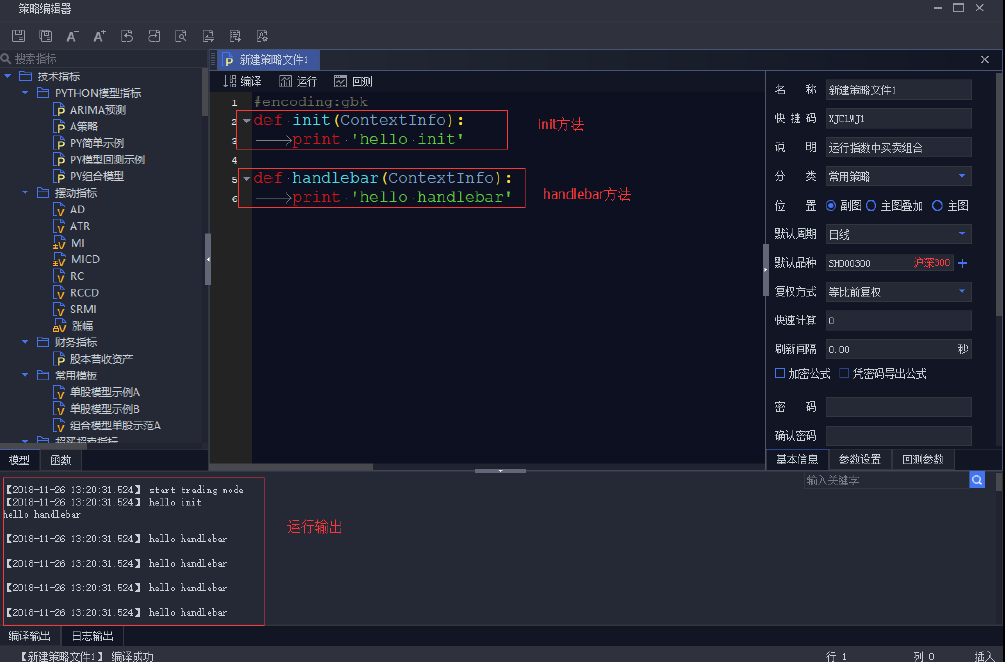
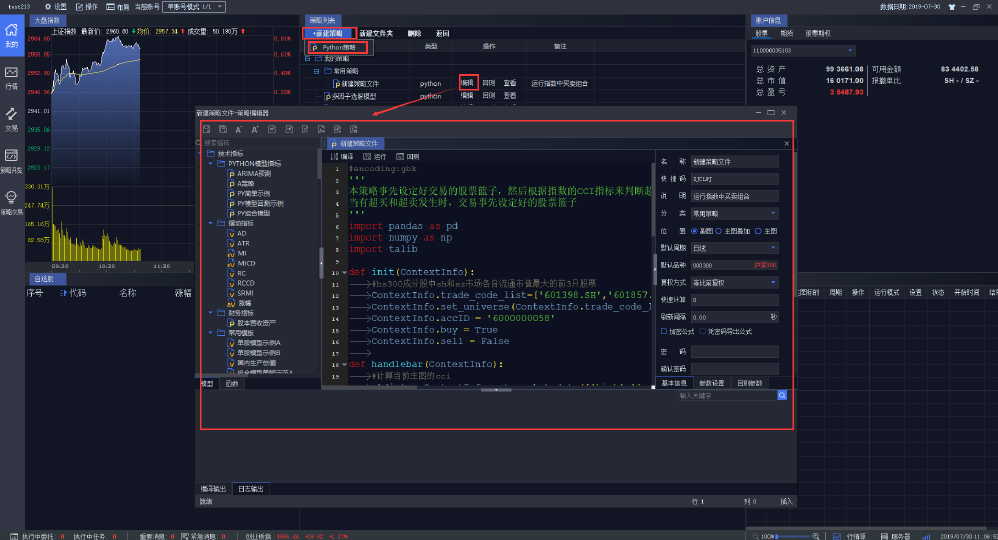
量化交易平台下载 2024-09-23 22:28:06 星期一{mtitle title="量化平台下载使用"/}{lamp/}{timeline}{timeline-item color="#19be6b"} 正式上线{/timeline-item}{timeline-item color="#ed4014"} 删库跑路{/timeline-item}{/timeline}点击下面文字下载:iQuant策略交易平台 新建一个 Python 策略 方法一,使用系统预置的各种示例模型,点击后方“编辑'按钮,并在弹出的【策略编辑器】中以此示例模型代码为基础进行编写。或者点击新建模型,选择 Python 模型,在弹出的【策略编辑器】中从头到尾编写一个用户自己的量化模型。方法二,在【策略开发】界面,使用系统预置的各种示例模型,点击后方“编辑'按钮,并在弹出的【策略编辑器】中以此示例模型代码为基础进行编写。或者点击新建模型,选择 Python 模型,在弹出的【策略编辑器】中从头到尾编写一个用户自己的量化模型。方法三,在模型管理面板右键,选择新建模型,并选择 Python 模型。
-