搜索到
81
篇与
的结果
-
 分布式机器学习 分布式机器学习涉及将机器学习算法的训练过程分布到多个计算资源上,以加快训练速度并处理大规模数据集。这个过程中涉及多个核心概念和技术,以下是一些主要知识点:1. 分布式架构 参数服务器(Parameter Server):一种常用的分布式训练架构,其中模型参数在一个或多个参数服务器上维护,而工作节点负责计算梯度。环形All-reduce(Ring All-reduce):一种高效的数据汇总技术,用于在工作节点间同步更新模型参数,适用于大规模并行训练。 2. 数据和模型并行性 数据并行(Data Parallelism):每个节点拷贝完整模型,但只处理数据的一个子集,之后同步更新模型参数。模型并行(Model Parallelism):模型的不同部分分布在不同的节点上,每个节点只处理模型的一部分。 3. 同步与异步更新 同步SGD(Synchronous SGD):所有工作节点在更新模型参数前,必须等待所有其他节点完成计算,以保持参数同步。异步SGD(Asynchronous SGD):每个工作节点更新模型参数无需等待其他节点,可以减少等待时间,但可能导致更新冲突。 4. 优化策略和技巧 梯度累积(Gradient Accumulation):在执行参数更新前累积多个小批量(mini-batch)的梯度,用于平衡计算和通信开销。梯度压缩(Gradient Compression):减少在节点间传输的数据量,通过压缩梯度以加速通信。容错机制(Fault Tolerance):在分布式训练过程中,处理节点故障和网络问题的能力。 5. 框架和工具TensorFlow描述:由Google开发的开源机器学习库,支持分布式训练。特点:强大的计算图抽象。广泛的API支持,包括Python和C++。提供了tf.distribute.StrategyAPI来简化分布式训练。支持多种硬件,包括CPU、GPU和TPU。PyTorch描述:由Facebook开发的开源机器学习库,支持动态计算图。特点:动态计算图使得模型易于调试和理解。torch.distributed包提供了分布式训练的支持。拥有活跃的社区和丰富的库资源。支持GPU加速。Apache Spark MLlib描述:基于Apache Spark的大规模机器学习库。特点:设计用于大规模数据处理的分布式计算框架。提供了数据预处理、特征提取、模型评估等丰富的机器学习算法。可以在Hadoop生态系统中使用,支持多种数据源。Horovod描述:由Uber开源的分布式训练框架,以TensorFlow、Keras、PyTorch和Apache MXNet为后端。特点:通过简单的几行代码改动,就可以实现分布式训练。使用环形All-reduce算法高效地同步梯度。支持在多个GPU和多个节点上训练。Dask-ML描述:基于Dask的并行计算库,用于扩展Scikit-learn等Python科学计算库。特点:支持大规模数据集的并行计算。与Pandas、NumPy、Scikit-learn等库紧密集成。可以在单机多核或分布式集群上运行。Microsoft CNTK描述:微软认知工具包(Cognitive Toolkit)是一个深度学习框架,支持分布式训练。特点:高性能的深度学习框架。支持RNN、CNN和LSTM等模型。提供了丰富的例子和教程。H2O描述:一个开源的、分布式的机器学习平台。特点:提供自动化的机器学习(AutoML)功能。支持广泛的统计和机器学习算法。提供了易于使用的Web界面和REST API。这些框架各有特点,选择哪个框架取决于具体的应用场景、团队的技能和项目的需求。在进行分布式机器学习项目时,了解每个框架的优势和局限性对于构建高效、可扩展的解决方案至关重要。 6. 应用场景 大规模数据处理:分布式训练可以有效处理超出单个计算资源内存限制的大数据集。复杂模型训练:对于参数量巨大的深度学习模型,分布式训练可以加速训练过程。分布式机器学习是解决大规模数据分析和复杂模型训练的关键技术。了解上述知识点有助于在实际应用中设计和实施有效的分布式机器学习解决方案。要实现一个分布式机器学习示例,我们可以使用TensorFlow和它的tf.distribute.Strategy API来演示数据并行。下面的代码示例将演示如何使用tf.distribute.MirroredStrategy来在多个GPU上进行简单的模型训练。这种策略适用于单机多GPU环境,它会在所有可用的GPU上复制模型,并在每个步骤中同步更新模型的参数。首先,确保你的环境中安装了TensorFlow。如果未安装,可以通过运行pip install tensorflow来安装。import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Flatten from tensorflow.keras.optimizers import Adam # 加载MNIST数据集 (train_images, train_labels), (test_images, test_labels) = mnist.load_data() # 数据预处理 train_images = train_images / 255.0 test_images = test_images / 255.0 # 定义一个简单的序贯模型 def create_model(): model = Sequential([ Flatten(input_shape=(28, 28)), Dense(128, activation='relu'), Dense(10) ]) model.compile(optimizer=Adam(), loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # 使用MirroredStrategy进行分布式训练 strategy = tf.distribute.MirroredStrategy() print('Number of devices: {}'.format(strategy.num_replicas_in_sync)) # 创建和编译模型 with strategy.scope(): model = create_model() # 训练模型 model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels)) 在这个例子中,tf.distribute.MirroredStrategy 自动处理了数据的分发到各个GPU,模型的复制以及梯度的汇总和应用。这使得在多个GPU上进行模型训练变得非常简单。请注意,执行分布式训练需要有多个GPU。如果你在没有多个GPU的环境(例如,普通笔记本电脑)中运行上述代码,它仍然会工作,但实际上并不是在进行分布式训练。在有多个GPU的环境中,你会看到加速效果。此代码示例提供了一个基本的分布式训练的入门点。根据你的具体需求和环境配置,可能还需要进行一些调整。
分布式机器学习 分布式机器学习涉及将机器学习算法的训练过程分布到多个计算资源上,以加快训练速度并处理大规模数据集。这个过程中涉及多个核心概念和技术,以下是一些主要知识点:1. 分布式架构 参数服务器(Parameter Server):一种常用的分布式训练架构,其中模型参数在一个或多个参数服务器上维护,而工作节点负责计算梯度。环形All-reduce(Ring All-reduce):一种高效的数据汇总技术,用于在工作节点间同步更新模型参数,适用于大规模并行训练。 2. 数据和模型并行性 数据并行(Data Parallelism):每个节点拷贝完整模型,但只处理数据的一个子集,之后同步更新模型参数。模型并行(Model Parallelism):模型的不同部分分布在不同的节点上,每个节点只处理模型的一部分。 3. 同步与异步更新 同步SGD(Synchronous SGD):所有工作节点在更新模型参数前,必须等待所有其他节点完成计算,以保持参数同步。异步SGD(Asynchronous SGD):每个工作节点更新模型参数无需等待其他节点,可以减少等待时间,但可能导致更新冲突。 4. 优化策略和技巧 梯度累积(Gradient Accumulation):在执行参数更新前累积多个小批量(mini-batch)的梯度,用于平衡计算和通信开销。梯度压缩(Gradient Compression):减少在节点间传输的数据量,通过压缩梯度以加速通信。容错机制(Fault Tolerance):在分布式训练过程中,处理节点故障和网络问题的能力。 5. 框架和工具TensorFlow描述:由Google开发的开源机器学习库,支持分布式训练。特点:强大的计算图抽象。广泛的API支持,包括Python和C++。提供了tf.distribute.StrategyAPI来简化分布式训练。支持多种硬件,包括CPU、GPU和TPU。PyTorch描述:由Facebook开发的开源机器学习库,支持动态计算图。特点:动态计算图使得模型易于调试和理解。torch.distributed包提供了分布式训练的支持。拥有活跃的社区和丰富的库资源。支持GPU加速。Apache Spark MLlib描述:基于Apache Spark的大规模机器学习库。特点:设计用于大规模数据处理的分布式计算框架。提供了数据预处理、特征提取、模型评估等丰富的机器学习算法。可以在Hadoop生态系统中使用,支持多种数据源。Horovod描述:由Uber开源的分布式训练框架,以TensorFlow、Keras、PyTorch和Apache MXNet为后端。特点:通过简单的几行代码改动,就可以实现分布式训练。使用环形All-reduce算法高效地同步梯度。支持在多个GPU和多个节点上训练。Dask-ML描述:基于Dask的并行计算库,用于扩展Scikit-learn等Python科学计算库。特点:支持大规模数据集的并行计算。与Pandas、NumPy、Scikit-learn等库紧密集成。可以在单机多核或分布式集群上运行。Microsoft CNTK描述:微软认知工具包(Cognitive Toolkit)是一个深度学习框架,支持分布式训练。特点:高性能的深度学习框架。支持RNN、CNN和LSTM等模型。提供了丰富的例子和教程。H2O描述:一个开源的、分布式的机器学习平台。特点:提供自动化的机器学习(AutoML)功能。支持广泛的统计和机器学习算法。提供了易于使用的Web界面和REST API。这些框架各有特点,选择哪个框架取决于具体的应用场景、团队的技能和项目的需求。在进行分布式机器学习项目时,了解每个框架的优势和局限性对于构建高效、可扩展的解决方案至关重要。 6. 应用场景 大规模数据处理:分布式训练可以有效处理超出单个计算资源内存限制的大数据集。复杂模型训练:对于参数量巨大的深度学习模型,分布式训练可以加速训练过程。分布式机器学习是解决大规模数据分析和复杂模型训练的关键技术。了解上述知识点有助于在实际应用中设计和实施有效的分布式机器学习解决方案。要实现一个分布式机器学习示例,我们可以使用TensorFlow和它的tf.distribute.Strategy API来演示数据并行。下面的代码示例将演示如何使用tf.distribute.MirroredStrategy来在多个GPU上进行简单的模型训练。这种策略适用于单机多GPU环境,它会在所有可用的GPU上复制模型,并在每个步骤中同步更新模型的参数。首先,确保你的环境中安装了TensorFlow。如果未安装,可以通过运行pip install tensorflow来安装。import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Flatten from tensorflow.keras.optimizers import Adam # 加载MNIST数据集 (train_images, train_labels), (test_images, test_labels) = mnist.load_data() # 数据预处理 train_images = train_images / 255.0 test_images = test_images / 255.0 # 定义一个简单的序贯模型 def create_model(): model = Sequential([ Flatten(input_shape=(28, 28)), Dense(128, activation='relu'), Dense(10) ]) model.compile(optimizer=Adam(), loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # 使用MirroredStrategy进行分布式训练 strategy = tf.distribute.MirroredStrategy() print('Number of devices: {}'.format(strategy.num_replicas_in_sync)) # 创建和编译模型 with strategy.scope(): model = create_model() # 训练模型 model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels)) 在这个例子中,tf.distribute.MirroredStrategy 自动处理了数据的分发到各个GPU,模型的复制以及梯度的汇总和应用。这使得在多个GPU上进行模型训练变得非常简单。请注意,执行分布式训练需要有多个GPU。如果你在没有多个GPU的环境(例如,普通笔记本电脑)中运行上述代码,它仍然会工作,但实际上并不是在进行分布式训练。在有多个GPU的环境中,你会看到加速效果。此代码示例提供了一个基本的分布式训练的入门点。根据你的具体需求和环境配置,可能还需要进行一些调整。 -
第10章深度学习之神经网络主要知识点 深度学习是机器学习的一个分支,它利用深度神经网络来模拟人脑的处理方式,以解决复杂的模式识别和信号处理问题。深度神经网络包含多层处理单元,能够从大量数据中学习表示和特征。以下是深度学习中涉及的一些核心神经网络知识点:1. 基本概念 神经元:神经网络的基本单位,模拟生物神经元的功能。权重和偏置:神经元的参数,用于控制输入数据如何转换为输出。激活函数:引入非线性因素,使网络能够学习复杂的模式,常见的激活函数包括ReLU、Sigmoid和Tanh。 2. 网络结构 前馈神经网络(Feedforward Neural Networks):数据在这种网络中只向前传递。卷积神经网络(CNNs):特别适合图像处理,通过卷积层自动提取空间特征。循环神经网络(RNNs):适用于序列数据处理,如语言模型和时间序列分析,能够处理前后数据点之间的依赖关系。长短期记忆网络(LSTMs)和门控循环单元(GRUs):RNN的变体,解决了传统RNN在处理长序列数据时的梯度消失或爆炸问题。 3. 训练神经网络 损失函数:评估模型的预测值与实际值之间的差异,常见的有均方误差、交叉熵等。优化算法:用于最小化(或最大化)损失函数,以训练模型的参数,包括梯度下降、随机梯度下降(SGD)、Adam等。反向传播:一种高效计算梯度的技术,用于在网络中传播误差,并更新权重和偏置。 4. 正则化和避免过拟合 过拟合:模型在训练数据上表现很好,但在新数据上表现差。正则化技术:如L1和L2正则化、Dropout、批量归一化(Batch Normalization),用于减少过拟合,提高模型的泛化能力。 5. 深度学习框架 TensorFlow和Keras:Google开发的开源框架,支持灵活的研究和高效的生产部署。PyTorch:Facebook的开源框架,以其动态计算图和易用性受到广泛欢迎。 6. 应用领域 计算机视觉:图像分类、对象检测、图像生成等。自然语言处理:语言翻译、情感分析、文本生成等。声音处理:语音识别、音乐生成等。深度学习是一个快速发展的领域,不断有新的研究和技术出现。掌握上述基础知识点将有助于深入理解和应用深度学习。
-
利用机器学习进行实证分析 假设我们的研究目标是分析经济指标对股市的影响。第一步:明确研究问题和假设 研究问题:经济增长率、失业率和通货膨胀率如何影响股市指数?研究假设:经济增长率正向影响股市指数,而失业率和通货膨胀率负向影响股市指数。第二步:数据收集 数据可以从公开数据库如国家统计局、经济研究机构、股市交易所等地方获得。为简化,我们假设这些数据已经收集完毕,保存在CSV文件中。第三步:数据预处理 数据预处理是数据分析中最重要的步骤之一,它直接影响到分析的质量和结果的可靠性。示例代码:import pandas as pd # 加载数据 data = pd.read_csv('economic_and_stock_data.csv') # 查看数据的前几行,以了解其结构 print(data.head()) # 检查并处理缺失值 if data.isnull().sum().sum() > 0: # 假设我们决定填充缺失值 data.fillna(method='ffill', inplace=True) # 转换日期格式 data['date'] = pd.to_datetime(data['date']) 第四步:探索性数据分析(EDA) 在构建任何统计或机器学习模型之前,对数据进行探索性分析是非常有帮助的。这可以使用图表来完成,比如散点图、线图和直方图,它们可以揭示变量间的关系和分布特征。示例代码:import matplotlib.pyplot as plt import seaborn as sns # 绘制经济增长率和股市指数的关系 sns.lineplot(x='date', y='growth_rate', data=data, label='Economic Growth Rate') ax2 = plt.twinx() sns.lineplot(x='date', y='stock_index', data=data, color='r', ax=ax2, label='Stock Market Index') plt.title('Economic Growth Rate vs. Stock Market Index') plt.show() 第五步:建立统计模型 根据研究问题和假设,选择适当的统计模型来分析数据。在我们的示例中,我们可以使用多元线性回归模型来分析经济指标与股市指数之间的关系。示例代码:from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # 选择模型变量 X = data[['growth_rate', 'unemployment_rate', 'inflation_rate']] y = data['stock_index'] # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 建立和训练模型 model = LinearRegression() model.fit(X_train, y_train) # 模型评估 predictions = model.predict(X_test) print('RMSE:', mean_squared_error(y_test, predictions, squared=False)) 第六步:结果解释和撰写报告 根据模型的输出,解释每个经济指标对股市指数的影响,并将这些发现整理成毕业论文的一部分。应该包括模型的系数、显著性水平(P值)和模型的整体拟合度(例如,R²值)。在第六步中,我们会深入解释模型结果并撰写报告。因为这一步涉及到对模型输出的详细解释,所以不像前面的步骤那样主要依赖代码。然而,我会提供一个示例,展示如何从模型获取关键的统计指标,并解释这些指标的意义。假设你已经使用statsmodels库构建了一个多元线性回归模型,我们现在将从这个模型中提取系数、P值、R²值等统计量,并讨论如何解释这些结果。import statsmodels.api as sm # 假设X和y已经定义并准备好 X = sm.add_constant(X) # 添加常数项 model = sm.OLS(y, X).fit() # 拟合模型 # 打印模型的详细摘要 print(model.summary()) model.summary()将提供一个包含以下关键信息的表格:系数(Coefficients):每个自变量对因变量的影响。如果系数为正,表明该变量正向影响因变量;如果为负,则负向影响。标准误(Std. Error):系数估计的标准误差,衡量估计值的精确度。t值(t)和P值(P>|t|):t值衡量系数与其标准误之间的比例,用于测试假设(即该系数是否显著不为零)。P值则告诉我们,如果在零假设下(该系数实际上为零)观察到的数据(或更极端的数据)出现的概率。通常,P值小于0.05被认为是统计学上显著的。R²:模型解释的变异性百分比。值越接近1,说明模型拟合度越好。解释示例:假设你得到了以下输出(这只是一个假设的例子):经济增长率的系数为2.5,P值<0.01。这意味着经济增长率对股市指数有显著的正向影响,且这个结果是统计学上显著的。失业率的系数为-1.2,P值<0.05。这表明失业率与股市指数负相关,且这种影响是显著的。通货膨胀率的系数为-0.3,但P值为0.2。尽管系数为负,表明通货膨胀率可能对股市指数有负面影响,但这个结果在统计学上不显著。模型的R²值为0.85,表明模型能够解释85%的因变量(股市指数)变异。在报告中撰写:在撰写报告时,你应该详细说明每个变量的影响,解释它们如何影响股市指数,同时解释统计学上的显著性意味着什么。对于不显著的结果,讨论可能的原因和经济学意义也很重要。最后,讨论模型的整体拟合度(如R²值)以及这意味着你的模型在多大程度上能够解释股市指数的变化。记得,撰写科学报告时要清晰、准确地传达你的发现,并且以数据和统计结果为支撑。这样的解释和讨论将成为你毕业论文的重要部分,帮助读者理解你的研究成果及其意义。第七步:结果可视化 最后,为了使你的发现更容易被理解,应该将结果以图形的形式展现出来,例如,通过绘制实际值与预测值的比较图。示例代码:# 绘制实际值和预测值 plt.scatter(y_test, predictions) plt.xlabel('Actual Values') plt.ylabel('Predicted Values') plt.title('Actual vs. Predicted Stock Market Index') plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=4) plt.show() 以上步骤提供了使用Python进行毕业论文实证分析的一个框架,每一步都可以根据具体的研究目标和数据集进行调整。希望这能帮助你更好地理解如何利用Python来支持你的学术研究。
-
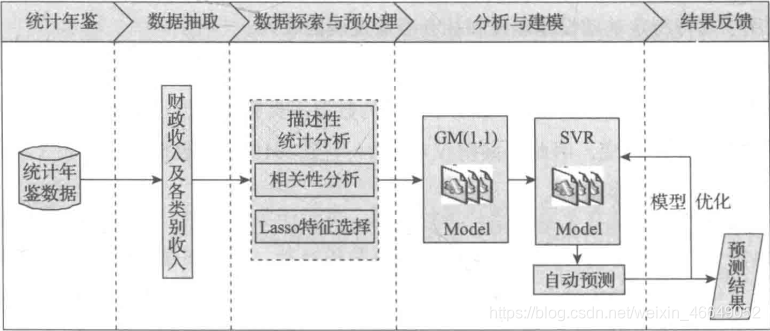
机器学习实训3 市财政收入分析 本文运用数据挖掘技术对市财政收入进行分析,挖掘其中的隐藏的运行模式,并对未来两年的财政收入进行预测,希望能够帮助政府合理地控制财政收支,优化财政建设,为制定相关决策提供依据。定义数据挖掘目标如下:分析、识别影响地方财政收入的关键属性预测2014年和2015年的财政收入本文数据挖掘主要包括以下步骤:对原始数据进行探索性分析,了解原始属性之间的相关性利用Lasso特征选择模型提取关键属性建立单个属性的灰色预测模型以及支持向量模回归预测模型使用支持向量回归预测模型得出2014年至2015年财政收入的预测值模型评价——————————————数据下载:https://siot-share.lenovo.com.cn/s/#/j0.tr92NBefSbt6LCFzB6提取码:a70m
-
機械学習とは? 機械学習(きかいがくしゅう、英: machine learning)とは、経験からの学習により自動で改善するコンピューターアルゴリズムもしくはその研究領域で1、人工知能の一種であるとみなされている。典型的には「訓練データ」もしくは「学習データ」と呼ばれるデータを使って学習し、学習結果を使って何らかのタスクをこなすものとされる。例えば過去のスパムメールを訓練データとして用いて学習し、スパムフィルタリングというタスクをこなす、といったものである。定義A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E[3]。 コンピュータプログラムがタスクのクラスTと性能指標Pに関し経験Eから学習するとは、T内のタスクのPで測った性能が経験Eにより改善される事を言う。— トム・M・ミッチェルここでタスクとは、プログラムが解くべき課題を指し、例えば売上予測タスクであれば「明日の売上を予測せよ」といったタスクである。経験はなんらかのデータとしてプログラムに与えられる。このデータを訓練データもしくは学習データといい、売上予測タスクであれば例えば「過去の経験」である今日までの売上が訓練データとして与えられる。訓練データを使ってプログラムの性能を改善する過程を、「プログラムを訓練する」もしくは「プログラムを学習させる」という。またプログラムの訓練に用いられるデータ全体の集合を(訓練もしくは学習)データセット(データ集合とも)という。最後に性能指標は、プログラムがタスクをどの程度の性能で達成したかを測る指標で、前述の売上予測タスクであれば、例えば実際の売上との誤差を性能指標として用いる事ができる。機械学習は以下の分野と密接に関係する:計算統計学(英語版):計算機を使った予測に焦点を当てた分野数理最適化:定められた条件下における最適解の探索に焦点を当てた分野データマイニング:教師なし学習(後述)における探索的データ解析に焦点を当てた分野注 1機械学習という名前は1959年にアーサー・サミュエルによって造語された[6]。理論機械学習アルゴリズムとその性能についての分析は、理論計算機科学の一分野であり、計算論的学習理論(英語版)と呼ばれている。訓練例は有限であるのに対して、未来は不確かであるため、学習理論は一般にアルゴリズムの性能を保証できない。その代わりに、性能の確率的範囲を与える。 Wassily Hoeffding(英語版)によるヘフディングの不等式(英語版)など統計的学習理論という表現もある[7]。それに加えて、学習の時間複雑性と実現可能性についても研究している。計算論的学習理論では、多項式時間で終了する計算を実現可能とみなす。機械学習と統計学は、多くの点で似ているが、使用する用語は異なる。